IEEE OCEANIC ENGINEERING SOCIETY -TECHNICAL ACTIVITY
An exciting virtual talk cum demonstration by Shyam Madhusudhana, Postdoctoral Fellow, K. Lisa Yang Center for Conservation Bioacoustics, Cornell Lab of Ornithology, Cornell University, USA
Moderator: Gopu R Potty, Assoc. Research Professor, University of Rhode Island
Contact: gpotty@uri.edu
Title: Machine learning in marine bioacoustics
Zoom Link: https://uri- edu.zoom.us/j/96392816010?pwd=Z0NFazAyeS9MSEZNczl3cHo2aW1nQT09
Date: 21st July 2021 Time: 8.30 PM EDT (0830hrs SGT)
The talk will be followed by an optional, informal networking session. Details will be provided at the time of the event
Abstract: Passive acoustic monitoring (PAM) methods are used for monitoring and studying a wide variety of soniferous marine fauna. The use of automatic recognition techniques has largely underpinned the successes of PAM undertakings by improving the ease and repeatability of analyses. Over the past decade, the adoption of machine learning (ML) based recognition techniques has brought about improved accuracy and reliability in mining large acoustic datasets, facilitating a suite of ecological studies, such as call- or cue-based density estimation, stock identification, or cultural transmissions.
This talk will provide an overview of PAM undertakings, present a brief overview of the various automation techniques used and contrast them with modern ML based techniques. We will present a gentle introduction to ML concepts as they apply to acoustic event recognition, and provide a hands-on demonstration of developing a ML model using real underwater acoustic recordings (please see attached instructions).
About the Speaker:
 Shyam Madhusudhana (shyamm@cornell.edu) is a postdoctoral researcher at the K. Lisa Yang Center for Conservation Bioacoustics (CCB) within the Cornell Lab of Ornithology. His research interests are largely multidisciplinary as is his academic background–Bachelors in Engineering, Masters in Computer Science, and PhD in Applied Physics. He has also worked as a speech scientist for a leading Automatic Speech Recognition solutions provider. Prior to joining CCB, he has been a research associate at the Centre for Marine Science and Technology in Australia, a research associate at the National Institute of Oceanography, Goa, India and a postdoctoral research fellow at the Indian Institute of Science Education and Research in Tirupati, India. His current research involves developing deep-learning techniques for realizing effective and efficient machine-listening in the big-data realm, with applications in the monitoring of both marine and terrestrial fauna.
Shyam Madhusudhana (shyamm@cornell.edu) is a postdoctoral researcher at the K. Lisa Yang Center for Conservation Bioacoustics (CCB) within the Cornell Lab of Ornithology. His research interests are largely multidisciplinary as is his academic background–Bachelors in Engineering, Masters in Computer Science, and PhD in Applied Physics. He has also worked as a speech scientist for a leading Automatic Speech Recognition solutions provider. Prior to joining CCB, he has been a research associate at the Centre for Marine Science and Technology in Australia, a research associate at the National Institute of Oceanography, Goa, India and a postdoctoral research fellow at the Indian Institute of Science Education and Research in Tirupati, India. His current research involves developing deep-learning techniques for realizing effective and efficient machine-listening in the big-data realm, with applications in the monitoring of both marine and terrestrial fauna.
He is a Senior Member of IEEE, and currently serves as an Administrative Committee member in IEEE’s Oceanic Engineering Society (OES). He is also the Coordinator of Technology Committees in OES and a co-Chair of the Student Poster Competitions at the biannual OCEANS conference. He referees manuscripts for journals focused on animal bioacoustics, pattern recognition and machine learning.
Preparation for the hands-on demo:
As part of the session, we will be demonstrating the use of a machine learning (ML) based approach to automation of bioacoustic data analyses. The demonstration will follow a hands-on approach where the participants can follow along to experience developing and using a ML-based solution to automatic recognition using a dataset containing North Atlantic Right Whale (NARW) calls. Familiarity with the Python programming language would be handy, but not critical.
The dataset used for the exercise is a part of the publicly available annotated NARW recordings that were part of the 2013 Detection, Classification, Localization and Density Estimation (DCLDE) challenge [1]. The original dataset consists of 7 days of continuous underwater recordings, 4 of which were earmarked for training and the remaining 3 for testing. In the interest of time considering the short session, the demonstration will only utilize a subset comprising of 2 days of recording, one for training and one for testing. The chosen audio data was downsampled and compressed for efficiency. The corresponding manual annotations (comprising of the start and end times, and lower and upper frequency bounds of the calls) of the occurrence of NARW up-calls were converted into RavenPro selection table format, which present the data in a tab-limited text file format.
The demonstration during the workshop will utilize Google Colaboratory, which is a free platform (for non-commercial use) offering cloud computation facility. We assume that the participants have an account with Google (having a Gmail account will suffice). Clicking on the below link
https://drive.google.com/drive/folders/1xyLZf63ixLzXECHpbUB_Tf5V2UosOe62?usp=sharing
will take you to where the dataset for the workshop demo is available. Once on the page, create a link to the dataset from your Google Drive storage by selecting the ‘Add shortcut to Drive’ as shown below:
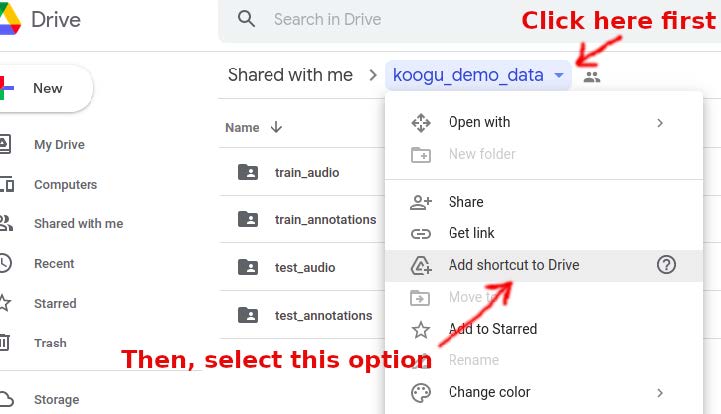
At the subsequent prompt, make sure “My Drive” is highlighted and then click on “ADD SHORTCUT”. This will create a “shared” folder link under your “My Drive”. You can verify this by clicking on the “Drive” icon at the top-left of the page and seeing that an item named “koogu_demo_data”. That’s it! Leave that item as is, and we will give you the program to process the data on the workshop day.
 Suleman Mazhar has been working as a professor in Information & Communication Engineering at Harbin Engineering University (China) since July 2019. He did PhD from Tokyo University (Japan) and postdoctorate from Georgetown University (Washington DC, USA). He had BS-CS from FAST-NUCES (Lahore) and MS from GIK Institute (Pakistan). He is TYSP young scientist fellow (Ministry of Science & Technology China) and have won several research grants from international organizations such as DAAD (Germany), ICIMOD (Nepal), NRPU (Higher Education Commission Pakistan), WWF (Worldwide Fund for Nature) Pakistan. His research focus is deep learning and signal processing applications for environmental monitoring, with particular focus on underwater acoustics, and marine mammal conservation. He is a reviewer for professional journals such as Journal of Acoustical Society (America), IEEE Journal of Oceanic Engineering, IEEE Sensors Journal, Applied Acoustics, IEEE Transactions on Intelligent Transportation Systems.
Suleman Mazhar has been working as a professor in Information & Communication Engineering at Harbin Engineering University (China) since July 2019. He did PhD from Tokyo University (Japan) and postdoctorate from Georgetown University (Washington DC, USA). He had BS-CS from FAST-NUCES (Lahore) and MS from GIK Institute (Pakistan). He is TYSP young scientist fellow (Ministry of Science & Technology China) and have won several research grants from international organizations such as DAAD (Germany), ICIMOD (Nepal), NRPU (Higher Education Commission Pakistan), WWF (Worldwide Fund for Nature) Pakistan. His research focus is deep learning and signal processing applications for environmental monitoring, with particular focus on underwater acoustics, and marine mammal conservation. He is a reviewer for professional journals such as Journal of Acoustical Society (America), IEEE Journal of Oceanic Engineering, IEEE Sensors Journal, Applied Acoustics, IEEE Transactions on Intelligent Transportation Systems. Peng Ren is a full professor with the College of Oceanography and Space Informatics, China University of Petroleum (East China). He is the director of Qingdao International Research Center for Intelligent Forecast and Detection of Oceanic Catastrophes. He received the K. M. Scott Prize from the University of York, the Natural Science award (first rank) from China Institute of Electronics, and the Eduardo Caianiello Best Student Paper Award from 18th International Conference on Image Analysis and Processing as one co-author. He has served as an associate editor of IEEE Transactions on Geoscience and Remote Sensing.
Peng Ren is a full professor with the College of Oceanography and Space Informatics, China University of Petroleum (East China). He is the director of Qingdao International Research Center for Intelligent Forecast and Detection of Oceanic Catastrophes. He received the K. M. Scott Prize from the University of York, the Natural Science award (first rank) from China Institute of Electronics, and the Eduardo Caianiello Best Student Paper Award from 18th International Conference on Image Analysis and Processing as one co-author. He has served as an associate editor of IEEE Transactions on Geoscience and Remote Sensing. Mohd Rizal Arshad is a full professor at the School of Electrical and Electronic Engineering at Universiti Sains Malaysia (USM), Malaysia, where he specializes in ocean robotics technology and intelligent system. He received his B.Eng. in Medical Electronics & Instrumentation and PhD in Electronic Engineering from University of Liverpool, UK in 1994 and 1999, respectively. He completed his MSc. in Electronic Control Engineering from the University of Salford, UK in Dec 1995. He has supervised many postgraduate students and published extensively in local and international publications. He is a senior member of the IEEE, and was awarded IEEE OES Presidential Award in 2019.
Mohd Rizal Arshad is a full professor at the School of Electrical and Electronic Engineering at Universiti Sains Malaysia (USM), Malaysia, where he specializes in ocean robotics technology and intelligent system. He received his B.Eng. in Medical Electronics & Instrumentation and PhD in Electronic Engineering from University of Liverpool, UK in 1994 and 1999, respectively. He completed his MSc. in Electronic Control Engineering from the University of Salford, UK in Dec 1995. He has supervised many postgraduate students and published extensively in local and international publications. He is a senior member of the IEEE, and was awarded IEEE OES Presidential Award in 2019. Itzik Klein is an Assistant Professor, heading the Autonomous Navigation and Sensor Fusion Lab, at the Charney School of Marine Sciences, Hatter Department of Marine Technologies, University of Haifa. He is an IEEE Senior Member and a member of the IEEE Journal of Indoor and Seamless Positioning and Navigation (J-ISPIN) Editorial Board. Prior to joining the University of Haifa, he worked at leading companies in Israel on navigation topics for more than 15 years. He has a wide range of experience in navigation systems and sensor fusion from both industry and academic perspectives. His research interests lie in the intersection of artificial intelligence with inertial sensing, sensor fusion, and autonomous underwater vehicles.
Itzik Klein is an Assistant Professor, heading the Autonomous Navigation and Sensor Fusion Lab, at the Charney School of Marine Sciences, Hatter Department of Marine Technologies, University of Haifa. He is an IEEE Senior Member and a member of the IEEE Journal of Indoor and Seamless Positioning and Navigation (J-ISPIN) Editorial Board. Prior to joining the University of Haifa, he worked at leading companies in Israel on navigation topics for more than 15 years. He has a wide range of experience in navigation systems and sensor fusion from both industry and academic perspectives. His research interests lie in the intersection of artificial intelligence with inertial sensing, sensor fusion, and autonomous underwater vehicles. John R. Potter (IEEE M’94, SM’02, F’18) graduated in the previous century with a joint honours Mathematics and Physics Degree from Bristol and a PhD. in Glaciology and Oceanography from Cambridge, UK studying Antarctic ice mass balance, where he spent four consecutive summers. This work helped underscore the non-linear fragility of polar ice to climate change and led to him receiving the Polar Medal from Queen Elizabeth II in 1988.
John R. Potter (IEEE M’94, SM’02, F’18) graduated in the previous century with a joint honours Mathematics and Physics Degree from Bristol and a PhD. in Glaciology and Oceanography from Cambridge, UK studying Antarctic ice mass balance, where he spent four consecutive summers. This work helped underscore the non-linear fragility of polar ice to climate change and led to him receiving the Polar Medal from Queen Elizabeth II in 1988. Nick is a Visiting Fellow at the UK National Oceanographic Center, Southampton His nomination was endorsed by the Underwater Acoustics Technology Committee. He had worked as a Research Associate and Lecturer at University of Birmingham and has been working as a Research Scientist at the Applied Research Laboratory, University of Texas, Austin. He has also served as a Program Officer at the Office of Naval Research Global. He is a senior member of IEEE (OES) and a Fellow of Acoustical Society of America (ASA). Nick has also been serving as Assoc. Editor for IEEE JoE and JASA. He is widely acknowledged for his expertise are seabed acoustics, parametric array modeling, sonar beamformer, underwater signal processing.
Nick is a Visiting Fellow at the UK National Oceanographic Center, Southampton His nomination was endorsed by the Underwater Acoustics Technology Committee. He had worked as a Research Associate and Lecturer at University of Birmingham and has been working as a Research Scientist at the Applied Research Laboratory, University of Texas, Austin. He has also served as a Program Officer at the Office of Naval Research Global. He is a senior member of IEEE (OES) and a Fellow of Acoustical Society of America (ASA). Nick has also been serving as Assoc. Editor for IEEE JoE and JASA. He is widely acknowledged for his expertise are seabed acoustics, parametric array modeling, sonar beamformer, underwater signal processing. Maurizio Migliaccio (M’91-SM’00-F’17) is Full professor of Electromagnetics at Università di Napoli Parthenope (Italy) and was Affiliated Full Professor at NOVA Southeastern University, Fort Lauderdale, FL (USA). He has been teaching Microwave Remote Sensing since 1994. He was visiting scientist at Deutsche Forschungsanstalt fur Lüft und Raumfahrt (DLR), Oberpfaffenhofen, Germany. He was member of the Italian Space Agency (ASI) scientific committee. He was member of the ASI CosmoSkyMed second generation panel. He was e-geos AdCom member. He was Italian delegate of the ESA PB-EO board. He was Member of South Africa Expert Review Panel for Space Exploration. He serves as reviewer for the UE, Italian Research Ministry (MIUR), NCST, Kazakhstan and Hong Kong Research board. He lectured in USA, Canada, Brazil, China, Hong Kong, Germany, Spain, Czech Republic, Switzerland and Italy. He was Italian delegate at UE COST SMOS Mode Action. He is listed in the Italian Top Scientists. He is an IEEE Trans. Geoscience and Remote Sensing AE, International Journal of Remote Sensing AE, and was IEEE Journal of Oceanic Engineering AE Special Issue on Radar for Marine and Maritime Remote Sensing, IEEE JSTARS AE of the Special Issue on CosmoSKyMed, Member of the Indian Journal of Radio & Space Physics Editorial board. His main current scientific interests cover SAR sea oil slick and man-made target monitoring, remote sensing for marine and coastal applications, remote sensing for agriculture monitoring, polarimetry, inverse problems for resolution enhancement, reverberating chambers. He published about 160 peer-reviewed journal papers on remote sensing and applied electromagnetics.
Maurizio Migliaccio (M’91-SM’00-F’17) is Full professor of Electromagnetics at Università di Napoli Parthenope (Italy) and was Affiliated Full Professor at NOVA Southeastern University, Fort Lauderdale, FL (USA). He has been teaching Microwave Remote Sensing since 1994. He was visiting scientist at Deutsche Forschungsanstalt fur Lüft und Raumfahrt (DLR), Oberpfaffenhofen, Germany. He was member of the Italian Space Agency (ASI) scientific committee. He was member of the ASI CosmoSkyMed second generation panel. He was e-geos AdCom member. He was Italian delegate of the ESA PB-EO board. He was Member of South Africa Expert Review Panel for Space Exploration. He serves as reviewer for the UE, Italian Research Ministry (MIUR), NCST, Kazakhstan and Hong Kong Research board. He lectured in USA, Canada, Brazil, China, Hong Kong, Germany, Spain, Czech Republic, Switzerland and Italy. He was Italian delegate at UE COST SMOS Mode Action. He is listed in the Italian Top Scientists. He is an IEEE Trans. Geoscience and Remote Sensing AE, International Journal of Remote Sensing AE, and was IEEE Journal of Oceanic Engineering AE Special Issue on Radar for Marine and Maritime Remote Sensing, IEEE JSTARS AE of the Special Issue on CosmoSKyMed, Member of the Indian Journal of Radio & Space Physics Editorial board. His main current scientific interests cover SAR sea oil slick and man-made target monitoring, remote sensing for marine and coastal applications, remote sensing for agriculture monitoring, polarimetry, inverse problems for resolution enhancement, reverberating chambers. He published about 160 peer-reviewed journal papers on remote sensing and applied electromagnetics. He has developed various types of Autonomous Underwater Vehicles (AUVs) and related application technologies including navigation methods, a new sensing method using a chemical sensor, precise seafloor mapping methods, a precise seabed positioning system with a resolution of a few centimeters, a new sensing system of the thickness of cobalt-rich crust; and more. He has shown, by using these technologies that AUVs are practicable and valuable tools for deep-sea exploration.
He has developed various types of Autonomous Underwater Vehicles (AUVs) and related application technologies including navigation methods, a new sensing method using a chemical sensor, precise seafloor mapping methods, a precise seabed positioning system with a resolution of a few centimeters, a new sensing system of the thickness of cobalt-rich crust; and more. He has shown, by using these technologies that AUVs are practicable and valuable tools for deep-sea exploration. Donna Kocak has had an outstanding career in defense and scientific projects developing and applying solutions in subsea optics, imaging and robotics. She graduated with an M.Sc in Computer Science in 1997 from the University of Central Florida; an MBA in 2008 from the University of Florida; and M.Sc in Industrial Engineering in 2011 from the University of Central Florida. She is currently a Senior Scientist, Advanced Concepts Engineering, and Fellow at the Harris Corporation in Melbourne, Florida, where she has developed novel optical imaging and communication solutions for under-sea defense and scientific projects. Prior to 2008 Donna Kocak was Founder and President of Green Sky Imaging, LLC (GSI) who developed laser/video photogrammetry software for underwater inspection and survey. Her earlier career positions were with Naval Training Systems Center, Florida; Harbor Branch Oceanographic Institution, Florida; eMerge Interactive; and the Advanced Technologies Group in Florida.
Donna Kocak has had an outstanding career in defense and scientific projects developing and applying solutions in subsea optics, imaging and robotics. She graduated with an M.Sc in Computer Science in 1997 from the University of Central Florida; an MBA in 2008 from the University of Florida; and M.Sc in Industrial Engineering in 2011 from the University of Central Florida. She is currently a Senior Scientist, Advanced Concepts Engineering, and Fellow at the Harris Corporation in Melbourne, Florida, where she has developed novel optical imaging and communication solutions for under-sea defense and scientific projects. Prior to 2008 Donna Kocak was Founder and President of Green Sky Imaging, LLC (GSI) who developed laser/video photogrammetry software for underwater inspection and survey. Her earlier career positions were with Naval Training Systems Center, Florida; Harbor Branch Oceanographic Institution, Florida; eMerge Interactive; and the Advanced Technologies Group in Florida. John Potter has a Joint Honours degree in Mathematics and Physics from Bristol University in the UK and a PhD in Glaciology and Oceanography from the University of Cambridge on research in the Antarctic, for which he was awarded the Polar Medal in 1988. John has worked on polar oceanography, underwater acoustics, ambient noise (including imaging), marine mammals, communications, IoUT, autonomous vehicles and strategic development. He has 40 years’ international experience working at the British Antarctic Survey in the UK, NATO in Italy, SIO in California, NUS in Singapore and most recently at NTNU in Norway. John is a Fellow of the IEEE and MTS, an Associate Editor for the IEEE Journal of Oceanic Engineering, IEEE OES Distinguished Lecturer, PADI Master Scuba Diver Trainer & an International Fellow of the Explorer’s Club.
John Potter has a Joint Honours degree in Mathematics and Physics from Bristol University in the UK and a PhD in Glaciology and Oceanography from the University of Cambridge on research in the Antarctic, for which he was awarded the Polar Medal in 1988. John has worked on polar oceanography, underwater acoustics, ambient noise (including imaging), marine mammals, communications, IoUT, autonomous vehicles and strategic development. He has 40 years’ international experience working at the British Antarctic Survey in the UK, NATO in Italy, SIO in California, NUS in Singapore and most recently at NTNU in Norway. John is a Fellow of the IEEE and MTS, an Associate Editor for the IEEE Journal of Oceanic Engineering, IEEE OES Distinguished Lecturer, PADI Master Scuba Diver Trainer & an International Fellow of the Explorer’s Club. Dr. James V. Candy is the Chief Scientist for Engineering and former Director of the Center for Advanced Signal & Image Sciences at the University of California, Lawrence Livermore National Laboratory. Dr. Candy received a commission in the USAF in 1967 and was a Systems Engineer/Test Director from 1967 to 1971. He has been a Researcher at the Lawrence Livermore National Laboratory since 1976 holding various positions including that of Project Engineer for Signal Processing and Thrust Area Leader for Signal and Control Engineering. Educationally, he received his B.S.E.E. degree from the University of Cincinnati and his M.S.E. and Ph.D. degrees in Electrical Engineering from the University of Florida, Gainesville. He is a registered Control System Engineer in the state of California. He has been an Adjunct Professor at San Francisco State University, University of Santa Clara, and UC Berkeley, Extension teaching graduate courses in signal and image processing. He is an Adjunct Full-Professor at the University of California, Santa Barbara. Dr. Candy is a Fellow of the IEEE and a Fellow of the Acoustical Society of America (ASA) and elected as a Life Member (Fellow) at the University of Cambridge (Clare Hall College). He is a member of Eta Kappa Nu and Phi Kappa Phi honorary societies. He was elected as a Distinguished Alumnus by the University of Cincinnati. Dr. Candy received the IEEE Distinguished Technical Achievement Award for the “development of model-based signal processing in ocean acoustics.” Dr. Candy was selected as a IEEE Distinguished Lecturer for oceanic signal processing as well as presenting an IEEE tutorial on advanced signal processing available through their video website courses. He was nominated for the prestigious Edward Teller Fellowship at Lawrence Livermore National Laboratory. Dr. Candy was awarded the Interdisciplinary Helmholtz-Rayleigh Silver Medal in Signal Processing/Underwater Acoustics by the Acoustical Society of America for his technical contributions. He has published over 225 journal articles, book chapters, and technical reports as well as written three texts in signal processing, “Signal Processing: the Model-Based Approach,” (McGraw-Hill, 1986), “Signal Processing: the Modern Approach,” (McGraw-Hill, 1988), “Model-Based Signal Processing,” (Wiley/IEEE Press, 2006) and “Bayesian Signal Processing: Classical, Modern and Particle Filtering” (Wiley/IEEE Press, 2009). He was the General Chairman of the inaugural 2006 IEEE Nonlinear Statistical Signal Processing Workshop held at the Corpus Christi College, University of Cambridge. He has presented a variety of short courses and tutorials sponsored by the IEEE and ASA in Applied Signal Processing, Spectral Estimation, Advanced Digital Signal Processing, Applied Model-Based Signal Processing, Applied Acoustical Signal Processing, Model-Based Ocean Acoustic Signal Processing and Bayesian Signal Processing for IEEE Oceanic Engineering Society/ASA. He has also presented short courses in Applied Model-Based Signal Processing for the SPIE Optical Society. He is currently the IEEE Chair of the Technical Committee on “Sonar Signal and Image Processing” and was the Chair of the ASA Technical Committee on “Signal Processing in Acoustics” as well as being an Associate Editor for Signal Processing of ASA (on-line JASAXL). He was recently nominated for the Vice Presidency of the ASA and elected as a member of the Administrative Committee of IEEE OES. His research interests include Bayesian estimation, identification, spatial estimation, signal and image processing, array signal processing, nonlinear signal processing, tomography, sonar/radar processing and biomedical applications.
Dr. James V. Candy is the Chief Scientist for Engineering and former Director of the Center for Advanced Signal & Image Sciences at the University of California, Lawrence Livermore National Laboratory. Dr. Candy received a commission in the USAF in 1967 and was a Systems Engineer/Test Director from 1967 to 1971. He has been a Researcher at the Lawrence Livermore National Laboratory since 1976 holding various positions including that of Project Engineer for Signal Processing and Thrust Area Leader for Signal and Control Engineering. Educationally, he received his B.S.E.E. degree from the University of Cincinnati and his M.S.E. and Ph.D. degrees in Electrical Engineering from the University of Florida, Gainesville. He is a registered Control System Engineer in the state of California. He has been an Adjunct Professor at San Francisco State University, University of Santa Clara, and UC Berkeley, Extension teaching graduate courses in signal and image processing. He is an Adjunct Full-Professor at the University of California, Santa Barbara. Dr. Candy is a Fellow of the IEEE and a Fellow of the Acoustical Society of America (ASA) and elected as a Life Member (Fellow) at the University of Cambridge (Clare Hall College). He is a member of Eta Kappa Nu and Phi Kappa Phi honorary societies. He was elected as a Distinguished Alumnus by the University of Cincinnati. Dr. Candy received the IEEE Distinguished Technical Achievement Award for the “development of model-based signal processing in ocean acoustics.” Dr. Candy was selected as a IEEE Distinguished Lecturer for oceanic signal processing as well as presenting an IEEE tutorial on advanced signal processing available through their video website courses. He was nominated for the prestigious Edward Teller Fellowship at Lawrence Livermore National Laboratory. Dr. Candy was awarded the Interdisciplinary Helmholtz-Rayleigh Silver Medal in Signal Processing/Underwater Acoustics by the Acoustical Society of America for his technical contributions. He has published over 225 journal articles, book chapters, and technical reports as well as written three texts in signal processing, “Signal Processing: the Model-Based Approach,” (McGraw-Hill, 1986), “Signal Processing: the Modern Approach,” (McGraw-Hill, 1988), “Model-Based Signal Processing,” (Wiley/IEEE Press, 2006) and “Bayesian Signal Processing: Classical, Modern and Particle Filtering” (Wiley/IEEE Press, 2009). He was the General Chairman of the inaugural 2006 IEEE Nonlinear Statistical Signal Processing Workshop held at the Corpus Christi College, University of Cambridge. He has presented a variety of short courses and tutorials sponsored by the IEEE and ASA in Applied Signal Processing, Spectral Estimation, Advanced Digital Signal Processing, Applied Model-Based Signal Processing, Applied Acoustical Signal Processing, Model-Based Ocean Acoustic Signal Processing and Bayesian Signal Processing for IEEE Oceanic Engineering Society/ASA. He has also presented short courses in Applied Model-Based Signal Processing for the SPIE Optical Society. He is currently the IEEE Chair of the Technical Committee on “Sonar Signal and Image Processing” and was the Chair of the ASA Technical Committee on “Signal Processing in Acoustics” as well as being an Associate Editor for Signal Processing of ASA (on-line JASAXL). He was recently nominated for the Vice Presidency of the ASA and elected as a member of the Administrative Committee of IEEE OES. His research interests include Bayesian estimation, identification, spatial estimation, signal and image processing, array signal processing, nonlinear signal processing, tomography, sonar/radar processing and biomedical applications. Kenneth Foote is a Senior Scientist at the Woods Hole Oceanographic Institution. He received a B.S. in Electrical Engineering from The George Washington University in 1968, and a Ph.D. in Physics from Brown University in 1973. He was an engineer at Raytheon Company, 1968-1974; postdoctoral scholar at Loughborough University of Technology, 1974-1975; research fellow and substitute lecturer at the University of Bergen, 1975-1981. He began working at the Institute of Marine Research, Bergen, in 1979; joined the Woods Hole Oceanographic Institution in 1999. His general area of expertise is in underwater sound scattering, with applications to the quantification of fish, other aquatic organisms, and physical scatterers in the water column and on the seafloor. In developing and transitioning acoustic methods and instruments to operations at sea, he has worked from 77°N to 55°S.
Kenneth Foote is a Senior Scientist at the Woods Hole Oceanographic Institution. He received a B.S. in Electrical Engineering from The George Washington University in 1968, and a Ph.D. in Physics from Brown University in 1973. He was an engineer at Raytheon Company, 1968-1974; postdoctoral scholar at Loughborough University of Technology, 1974-1975; research fellow and substitute lecturer at the University of Bergen, 1975-1981. He began working at the Institute of Marine Research, Bergen, in 1979; joined the Woods Hole Oceanographic Institution in 1999. His general area of expertise is in underwater sound scattering, with applications to the quantification of fish, other aquatic organisms, and physical scatterers in the water column and on the seafloor. In developing and transitioning acoustic methods and instruments to operations at sea, he has worked from 77°N to 55°S. René Garello, professor at Télécom Bretagne, Fellow IEEE, co-leader of the TOMS (Traitements, Observations et Méthodes Statistiques) research team, in Pôle CID of the UMR CNRS 3192 Lab-STICC.
René Garello, professor at Télécom Bretagne, Fellow IEEE, co-leader of the TOMS (Traitements, Observations et Méthodes Statistiques) research team, in Pôle CID of the UMR CNRS 3192 Lab-STICC. Professor Mal Heron is Adjunct Professor in the Marine Geophysical Laboratory at James Cook University in Townsville, Australia, and is CEO of Portmap Remote Ocean Sensing Pty Ltd. His PhD work in Auckland, New Zealand, was on radio-wave probing of the ionosphere, and that is reflected in his early ionospheric papers. He changed research fields to the scattering of HF radio waves from the ocean surface during the 1980s. Through the 1990s his research has broadened into oceanographic phenomena which can be studied by remote sensing, including HF radar and salinity mapping from airborne microwave radiometers . Throughout, there have been one-off papers where he has been involved in solving a problem in a cognate area like medical physics, and paleobiogeography. Occasionally, he has diverted into side-tracks like a burst of papers on the effect of bushfires on radio communications. His present project of the Australian Coastal Ocean Radar Network (ACORN) is about the development of new processing methods and applications of HF radar data to address oceanography problems. He is currently promoting the use of high resolution VHF ocean radars, based on the PortMap high resolution radar.
Professor Mal Heron is Adjunct Professor in the Marine Geophysical Laboratory at James Cook University in Townsville, Australia, and is CEO of Portmap Remote Ocean Sensing Pty Ltd. His PhD work in Auckland, New Zealand, was on radio-wave probing of the ionosphere, and that is reflected in his early ionospheric papers. He changed research fields to the scattering of HF radio waves from the ocean surface during the 1980s. Through the 1990s his research has broadened into oceanographic phenomena which can be studied by remote sensing, including HF radar and salinity mapping from airborne microwave radiometers . Throughout, there have been one-off papers where he has been involved in solving a problem in a cognate area like medical physics, and paleobiogeography. Occasionally, he has diverted into side-tracks like a burst of papers on the effect of bushfires on radio communications. His present project of the Australian Coastal Ocean Radar Network (ACORN) is about the development of new processing methods and applications of HF radar data to address oceanography problems. He is currently promoting the use of high resolution VHF ocean radars, based on the PortMap high resolution radar. Hanu Singh graduated B.S. ECE and Computer Science (1989) from George Mason University and Ph.D. (1995) from MIT/Woods Hole.He led the development and commercialization of the Seabed AUV, nine of which are in operation at other universities and government laboratories around the world. He was technical lead for development and operations for Polar AUVs (Jaguar and Puma) and towed vehicles(Camper and Seasled), and the development and commercialization of the Jetyak ASVs, 18 of which are currently in use. He was involved in the development of UAS for polar and oceanographic applications, and high resolution multi-sensor acoustic and optical mapping with underwater vehicles on over 55 oceanographic cruises in support of physical oceanography, marine archaeology, biology, fisheries, coral reef studies, geology and geophysics and sea-ice studies. He is an accomplished Research Student advisor and has made strong collaborations across the US (including at MIT, SIO, Stanford, Columbia LDEO) and internationally including in the UK, Australia, Canada, Korea, Taiwan, China, Japan, India, Sweden and Norway. Hanu Singh is currently Chair of the IEEE Ocean Engineering Technology Committee on Autonomous Marine Systems with responsibilities that include organizing the biennial IEEE AUV Conference, 2008 onwards. Associate Editor, IEEE Journal of Oceanic Engineering, 2007-2011. Associate editor, Journal of Field Robotics 2012 onwards.
Hanu Singh graduated B.S. ECE and Computer Science (1989) from George Mason University and Ph.D. (1995) from MIT/Woods Hole.He led the development and commercialization of the Seabed AUV, nine of which are in operation at other universities and government laboratories around the world. He was technical lead for development and operations for Polar AUVs (Jaguar and Puma) and towed vehicles(Camper and Seasled), and the development and commercialization of the Jetyak ASVs, 18 of which are currently in use. He was involved in the development of UAS for polar and oceanographic applications, and high resolution multi-sensor acoustic and optical mapping with underwater vehicles on over 55 oceanographic cruises in support of physical oceanography, marine archaeology, biology, fisheries, coral reef studies, geology and geophysics and sea-ice studies. He is an accomplished Research Student advisor and has made strong collaborations across the US (including at MIT, SIO, Stanford, Columbia LDEO) and internationally including in the UK, Australia, Canada, Korea, Taiwan, China, Japan, India, Sweden and Norway. Hanu Singh is currently Chair of the IEEE Ocean Engineering Technology Committee on Autonomous Marine Systems with responsibilities that include organizing the biennial IEEE AUV Conference, 2008 onwards. Associate Editor, IEEE Journal of Oceanic Engineering, 2007-2011. Associate editor, Journal of Field Robotics 2012 onwards. Milica Stojanovic graduated from the University of Belgrade, Serbia, in 1988, and received the M.S. and Ph.D. degrees in electrical engineering from Northeastern University in Boston, in 1991 and 1993. She was a Principal Scientist at the Massachusetts Institute of Technology, and in 2008 joined Northeastern University, where she is currently a Professor of electrical and computer engineering. She is also a Guest Investigator at the Woods Hole Oceanographic Institution. Milica’s research interests include digital communications theory, statistical signal processing and wireless networks, and their applications to underwater acoustic systems. She has made pioneering contributions to underwater acoustic communications, and her work has been widely cited. She is a Fellow of the IEEE, and serves as an Associate Editor for its Journal of Oceanic Engineering (and in the past for Transactions on Signal Processing and Transactions on Vehicular Technology). She also serves on the Advisory Board of the IEEE Communication Letters, and chairs the IEEE Ocean Engineering Society’s Technical Committee for Underwater Communication, Navigation and Positioning. Milica is the recipient of the 2015 IEEE/OES Distinguished Technical Achievement Award.
Milica Stojanovic graduated from the University of Belgrade, Serbia, in 1988, and received the M.S. and Ph.D. degrees in electrical engineering from Northeastern University in Boston, in 1991 and 1993. She was a Principal Scientist at the Massachusetts Institute of Technology, and in 2008 joined Northeastern University, where she is currently a Professor of electrical and computer engineering. She is also a Guest Investigator at the Woods Hole Oceanographic Institution. Milica’s research interests include digital communications theory, statistical signal processing and wireless networks, and their applications to underwater acoustic systems. She has made pioneering contributions to underwater acoustic communications, and her work has been widely cited. She is a Fellow of the IEEE, and serves as an Associate Editor for its Journal of Oceanic Engineering (and in the past for Transactions on Signal Processing and Transactions on Vehicular Technology). She also serves on the Advisory Board of the IEEE Communication Letters, and chairs the IEEE Ocean Engineering Society’s Technical Committee for Underwater Communication, Navigation and Positioning. Milica is the recipient of the 2015 IEEE/OES Distinguished Technical Achievement Award. Dr. Paul C. Hines was born and raised in Glace Bay, Cape Breton. From 1977-1981 he attended Dalhousie University, Halifax, Nova Scotia, graduating with a B.Sc. (Hon) in Engineering-Physics.
Dr. Paul C. Hines was born and raised in Glace Bay, Cape Breton. From 1977-1981 he attended Dalhousie University, Halifax, Nova Scotia, graduating with a B.Sc. (Hon) in Engineering-Physics.